

Tuttavia, i risultati del sondaggio quantitativo tra quei giornalisti erano piuttosto unilaterali. Riepilogo chatzipt “Il riepilogo medio delle tue formazioni corte può essere miscelato tra il resto delle tue formazioni corte, il riepilogo medio ha valutato solo 2,26 punteggio sulla scala da 1 (” no “) a 5 (a tutti”) da “Avaliti” compulsivamente “Avalità” di “Avaliti” 1 “Avalità” 1 “1”
Il valore non è aumentato
Agli scrittori è stato anche chiesto di scrivere una valutazione più qualitativa di sommazioni separate che sono state valutate. Gli autori si sono lamentati del fatto che il chatzp era spesso integrato con relazioni comuni e efficacia, non è riuscito a fornire il contesto (ad esempio, i acuteri morbidi erano molto lenti) e i risultati di sospensione di Honeyipe usando le parole come “rivoluzionario” e “romanzi” (sebbene questo fosse l’ultimo comportamento).
Nel complesso, i ricercatori hanno scoperto che il chatzp era generalmente bravo nel “replicare” ciò che è stato scritto su un documento scientifico, specialmente se quel documento non ha troppo sconvolto. Tuttavia, le procedure LLM, le restrizioni o l’impatto dell’immagine più grande, erano deboli per “tradurre” quelle ricerche. Questi punti deboli erano particolarmente veri nei documenti che offrono più risultati separati o quando a LLM è stato chiesto di riassumere due documenti correlati.
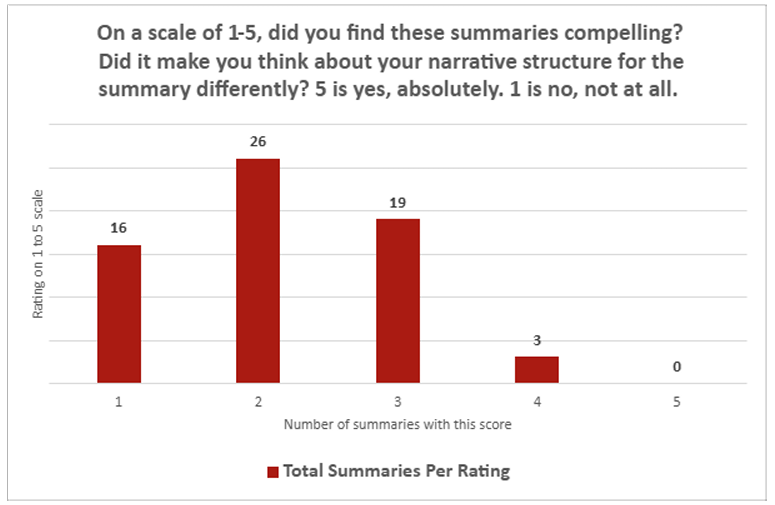
Questo riepilogo dell’intelligenza artificiale non è obbligatorio per me.
I giornalisti hanno scritto, sebbene la melodia e lo stile dei riassunti di chatzipt fosse spesso una buona somiglianza con i materiali di scrittura umana, “Axiety of True Accuracy nei contenuti di LLM-Writer” era prevalente, hanno scritto i giornalisti. Anche l’editing umano “sarà” punto iniziale “in quanto il” punto iniziale “richiederà più sforzi per redigere i cortometraggi da zero a causa di” ampio controllo dei fatti “necessaria per utilizzare il riepilogo.
Questi risultati potrebbero non essere molto sorprendenti per dare studi precedenti che i motori di ricerca AI hanno mostrato fonti di notizie errate che citano un tempo completo del 60 percento. Tuttavia, le debolezze specifiche sono più evidenti quando si discute di documenti scientifici, in cui l’accuratezza e la precisione della comunicazione sono universali.
Alla fine, i giornalisti AAS hanno raggiunto la conclusione che il Chatzpt “non soddisfa il riepilogo del pacchetto Skipak Press per il riepilogo e i valori”. Tuttavia, il white paper ha approvato che Chatzipt “sente un grande aggiornamento” se il test potrebbe essere appropriato se il test di nuovo. Per quello che vale, GPT -5 è stato introdotto al pubblico ad agosto.















{kind=link}