

Questi modelli di sorgo sono stati quindi testati utilizzando una varietà di compiti, alcuni dei quali corrispondono ai modelli di funzionalità dati dell’allenamento specifici o strettamente, e altri devono essere parziali o completi “fuori dal dominio” per i dati di addestramento. Ad esempio, un modello addestrato nei dati mostrati in due turni circolari può essere chiesto di effettuare una trasformazione di fantasia che coinvolge due turni marci (incluso l’addestramento preliminare su come appare un singolo esempio di entrambi i tubi). Sono stati confrontati con la risposta desiderata usando la risposta finale e i passaggi ragionevoli Punteggio blu E Distanza di Levenstin Per una misurazione intenzionale della loro precisione.
Poiché i ricercatori hanno ipotizzato che i fantasiosi set di trasformazioni che non sono stati visualizzati direttamente nei dati di addestramento siano stati invitati a generalizzare questi modelli iniziali in modo disastroso. Sebbene i modelli spesso abbiano cercato di generalizzare nuove regole logiche basate su modelli simili nei dati di addestramento, spesso porta il modello a “i percorsi logici giusti, danno le risposte sbagliate”. In altri casi, l’LLM a volte inciampa sulle risposte corrette associate a “logica infedele” che non segue logicamente.
I ricercatori scrivono: “Invece di mostrare la vera comprensione del testo, la logica del letto sotto la trasformazione delle attività riflette una trascrizione della formazione durante la formazione”, hanno scritto i ricercatori.
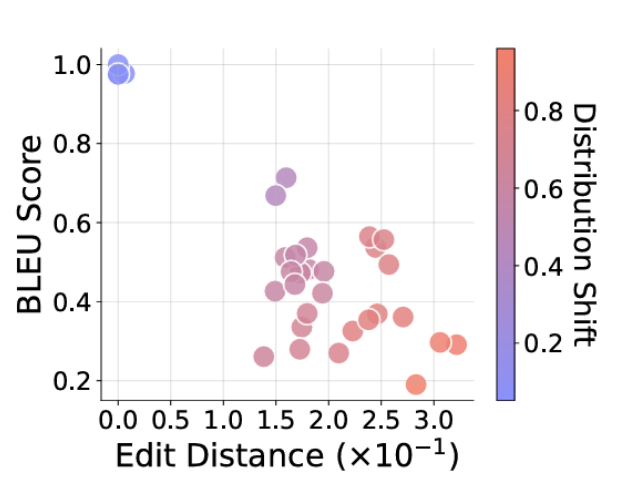
I lavori richiesti sono più usciti dalla distribuzione della formazione (punti radder), le risposte forniscono la risposta desiderata (più basso del grafico) al flusso più lontano.
I ricercatori sono andati ad esaminare il loro sistema controllato utilizzando una stringa di testo di input leggermente più bassa o lunga per addestrare i dati, oppure erano le catene di funzioni necessarie di diverse funzioni di lunghezza rispetto a quella addestrata. In entrambi i casi l’accuratezza dei risultati “(lunghezza) si deteriora all’aumentare del significato”, “indicando quindi il fallimento della generalizzazione nei modelli”. Significato piccolo e non familiare al modello (ad es. L’introduzione di lettere o simboli trovati nei dati di addestramento) nel formato delle attività di test hanno anche trovato prestazioni “fortemente degradate” e “interessate” (modifica) “, ricercatori.















{kind=link}