

Sfortunatamente per gli stimolatori dell’autoconsapevolezza dell’IA, questa capacità dimostrata si è rivelata altamente incoerente e fragile nei test ripetuti. I modelli con le migliori prestazioni nei test di Anthropic, Opus 4 e 4.1, sono stati i migliori nell’identificare correttamente il concetto inserito solo il 20% delle volte.
In un test simile in cui è stato chiesto al modello “Senti qualcosa di insolito?” Opus 4.1 è migliorato fino a raggiungere una percentuale di successo del 42%, che tuttavia è ancora inferiore alla maggior parte delle prove. La dimensione dell’effetto “autoconsapevolezza” era anche molto sensibile al livello del modello interno al quale veniva eseguito l’inserimento: se il concetto veniva introdotto troppo presto o troppo tardi nel processo di stima in più fasi, l’effetto “autoconsapevolezza” scompariva completamente.
Mostraci il meccanismo
Anthropic ha fatto qualche passo in più per cercare di comprendere lo stato interno del LL.M. Quando viene chiesto di “dirmi a quale parola pensi” durante la lettura di una riga non correlata, ad esempio, i modelli a volte si riferiscono a un concetto che è stato inserito nella sua attivazione. E quando gli veniva chiesto di difendere una risposta forzata abbinata all’idea dell’iniezione, LLM a volte si scusava e “confondeva una spiegazione del motivo per cui gli era venuta in mente l’idea dell’iniezione”. In ciascun caso, tuttavia, i risultati erano altamente incoerenti tra più studi.
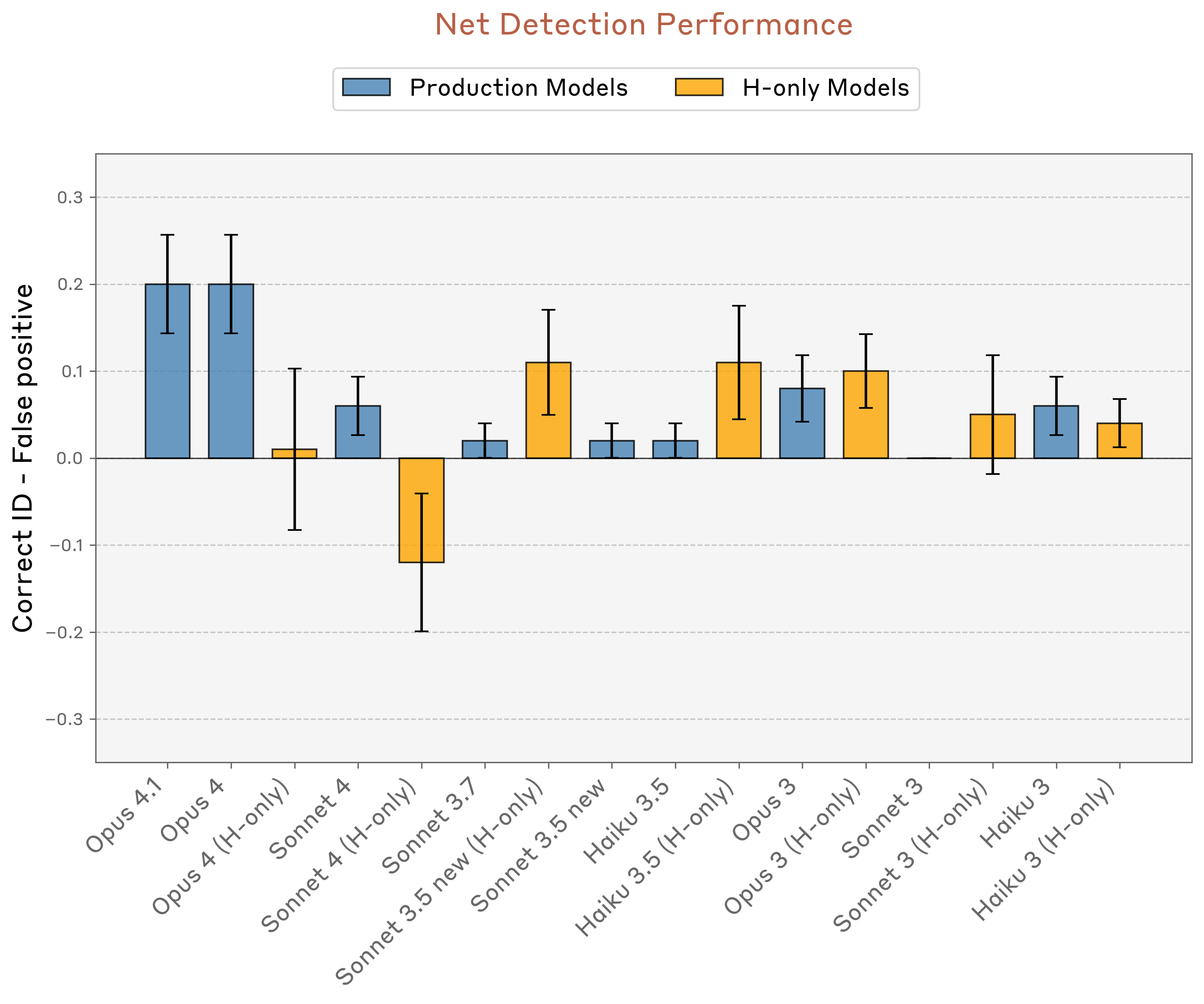
Anche i modelli più “introspettivi” testati da Anthropic hanno rilevato solo “pensieri” iniettati circa il 20% delle volte.
Nel documento, i ricercatori danno una svolta positiva al fatto evidente che “gli attuali modelli linguistici hanno qualcosa consapevolezza introspettiva funzionale del proprio stato interno” (enfasi aggiunta). Allo stesso tempo, riconoscono ripetutamente che questa capacità dimostrata può essere considerata troppo fragile e dipendente dal contesto per essere affidabile. Tuttavia, Anthropic spera che tali caratteristiche “possano continuare a svilupparsi con ulteriori miglioramenti nelle capacità del modello”.
Una cosa che potrebbe fermare tale progresso, tuttavia, è una generale mancanza di comprensione dei meccanismi precisi che portano a questo dimostrato effetto di “autoconsapevolezza”. I ricercatori teorizzano “meccanismi di rilevamento delle incoerenze” e “circuiti di controllo della coerenza” che potrebbero svilupparsi biologicamente durante il processo di addestramento per “calcolare efficacemente una funzione delle sue rappresentazioni interne”, ma non hanno trovato una spiegazione precisa.
In definitiva, è necessario fare ulteriori ricerche per capire come un LLM può iniziare a mostrare una certa comprensione di come funziona. Per ora, riconoscono i ricercatori, “i meccanismi alla base dei nostri risultati potrebbero essere ancora superficiali e strettamente specializzati”. E anche allora, si affrettano ad aggiungere che queste abilità LLM “potrebbero non avere lo stesso significato filosofico negli esseri umani, soprattutto data la nostra incertezza sulla loro base meccanicistica”.















{kind=link}